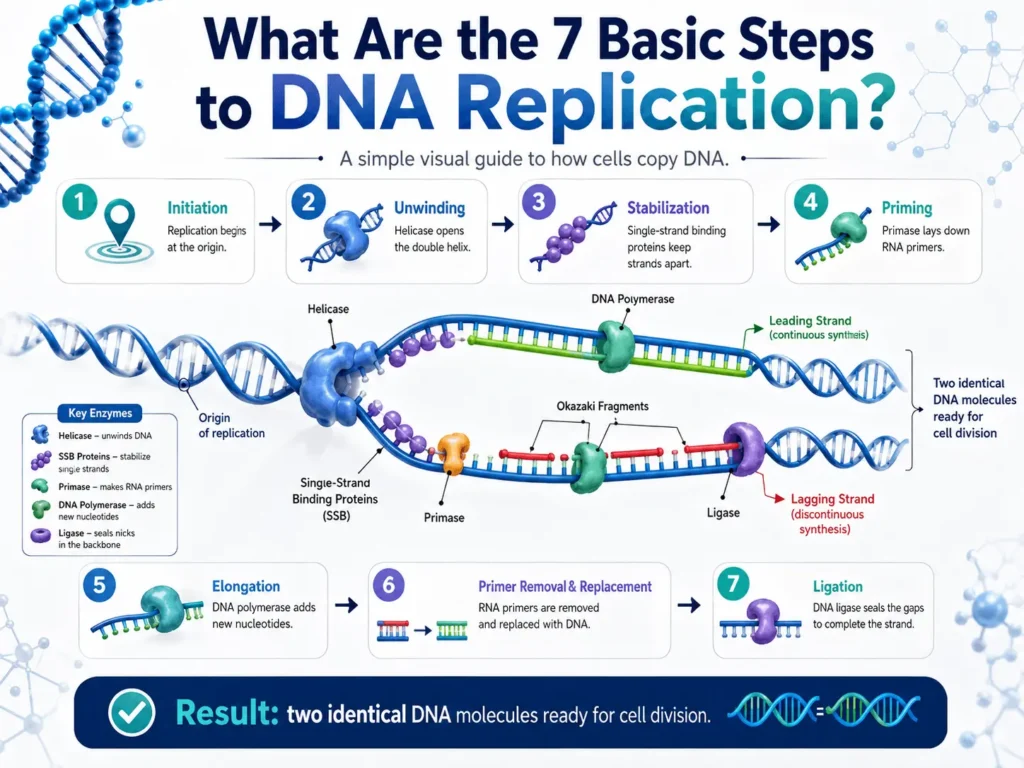
What Are the Seven Steps Involved in DNA Replication?
DNA replication is the process cells use to copy their genetic material before cell division. The process begins at a defined DNA sequence, where the double helix opens and each original strand becomes a template for a new matching strand. Proteins then stabilize the exposed DNA, build primers, add nucleotides, remove temporary RNA sections, seal the remaining gaps, and check the finished copy for errors.
The seven basic steps of DNA replication are origin recognition, DNA unwinding, strand stabilization, primer formation, new-strand synthesis, primer removal and gap filling, and DNA sealing with proofreading. These events often overlap rather than happening as seven completely separate actions.
The result is two DNA molecules. Each contains one original strand and one newly made strand, a pattern known as semiconservative replication.
What is DNA replication?
DNA replication is the copying of a cell’s DNA before it divides. Each parental DNA strand acts as a template that guides the construction of a complementary strand.
Human cells contain roughly 3 billion DNA base pairs in one copy of the genome. Before most cell divisions, that enormous set of genetic instructions must be copied so each daughter cell receives a full genome.
Replication takes place during the S phase, or synthesis phase, of the cell cycle. The cell does not simply split an existing DNA molecule between two daughter cells. It first produces a second copy and then distributes the duplicated chromosomes during cell division.
The process depends on complementary base pairing:
- Adenine pairs with thymine.
- Cytosine pairs with guanine.
When the two original strands separate, their base sequences tell the cell which nucleotides to place in the new strands. A template base containing adenine attracts thymine, while a template base containing cytosine attracts guanine.
What are the 7 basic steps to DNA replication?
The seven basic steps are:
- Replication begins at an origin.
- Helicase unwinds the DNA double helix.
- Proteins stabilize the separated strands.
- Primase builds RNA primers.
- DNA polymerase builds the new DNA strands.
- RNA primers are removed and replaced with DNA.
- DNA ligase seals the fragments while errors are checked and repaired.
This seven-step model makes a complicated molecular process easier to study. Inside a living cell, several of these activities happen at the same time around a moving replication fork.
1) Replication begins at an origin
DNA replication starts at a specific region called the origin of replication. Initiator proteins recognize this region, bind to it, and help recruit the other proteins needed to begin copying DNA.
An origin is not simply the first nucleotide at one end of a chromosome. It is a DNA sequence that can be recognized by replication-initiation proteins.
Bacterial chromosomes usually begin replication from a single main origin. Eukaryotic chromosomes, including human chromosomes, use many origins along each chromosome. Multiple starting points allow large chromosomes to be copied within a practical period.
Once an origin becomes active, the DNA opens in both directions. This creates a structure called a replication bubble. A Y-shaped replication fork forms at each end of the bubble.
The forks move away from the origin as copying continues. Replication is described as bidirectional because the two forks usually travel in opposite directions from the starting location.
Origins are controlled carefully. Starting twice at the same region could duplicate part of the genome more than once, while failing to activate enough origins could leave sections unreplicated.
Replication-initiation proteins help prepare each origin before DNA synthesis begins. In eukaryotic cells, origin preparation and origin activation are controlled during different parts of the cell cycle. This helps limit genome duplication to once per cycle.
2) Helicase unwinds the DNA double helix
After replication begins, an enzyme called DNA helicase separates the two parental DNA strands. Helicase moves along the DNA and disrupts the hydrogen bonds between paired bases.
The DNA molecule resembles a twisted ladder. The sugar-phosphate backbones form the sides, while paired nitrogenous bases form the rungs.
Before either strand can be copied, those paired bases must be pulled apart. Helicase performs this opening action using energy from ATP.
As helicase advances, it forms the Y-shaped replication fork. The separated parental strands can then serve as templates for new DNA.
Unwinding one section of a twisted molecule creates extra tension farther ahead. The DNA may become tightly coiled or supercoiled unless that tension is released.
Topoisomerase acts ahead of the replication fork. It temporarily cuts one or both DNA strands, allows the molecule to relax, and reconnects the DNA. This prevents excessive twisting from slowing or stopping the fork.
Helicase and topoisomerase have different jobs:
- Helicase separates the paired DNA strands at the fork.
- Topoisomerase relieves twisting ahead of the fork.
DNA replication could not continue efficiently without both actions. Helicase would keep opening the helix while the unopened DNA ahead became increasingly strained.
3) Single-strand binding proteins stabilize the open DNA
Once helicase separates the DNA strands, single-strand binding proteins attach to the exposed templates. These proteins keep the strands apart and protect them while copying takes place.
Separated DNA strands naturally tend to pair with complementary sequences again. They can also fold back on themselves and form structures that interfere with replication.
Single-strand binding proteins prevent these problems. In bacteria, they are usually called SSB proteins. In eukaryotes, a related protein complex called replication protein A, or RPA, performs this role.
These proteins do not copy DNA. They create a stable working surface for primase and DNA polymerase.
Their presence also protects single-stranded DNA from damage. Double-stranded DNA is normally more chemically stable than exposed single-stranded DNA, so leaving a template uncovered would increase its vulnerability.
At this stage, the replication fork contains several coordinated parts. Helicase continues opening the helix, topoisomerase releases tension, and binding proteins coat the newly separated strands.
These components work together as part of a larger protein assembly often called the replisome. The replisome keeps unwinding, priming, synthesis, and proofreading closely connected as the fork moves along the chromosome.
4) Primase builds RNA primers
DNA polymerase cannot begin a brand-new strand on bare DNA. It can only add nucleotides to an existing strand that has a free 3′ hydroxyl end.
A small starting section is needed. The enzyme primase produces this starting point by making a short RNA primer that pairs with the DNA template.
Unlike the main replicating DNA polymerases, primase can begin building a nucleic acid chain without an existing 3′ end. Once the primer is present, DNA polymerase can bind and extend it.
The leading strand usually needs one primer near the origin. The lagging strand needs many primers because it is built in separate sections.
In eukaryotic cells, the DNA polymerase alpha–primase complex begins the process. Primase produces a short RNA section, and polymerase alpha adds a short stretch of DNA. Other DNA polymerases then take over most of the longer synthesis work.
RNA primers are temporary. They help replication begin, but they are later removed and replaced with DNA.
This temporary use of RNA solves a molecular problem: the main DNA polymerases are highly accurate, but their structure prevents them from starting a chain from nothing. Primase sacrifices some of that accuracy in exchange for the ability to create a starting point.
5) DNA polymerase builds the new strands
DNA polymerase adds complementary DNA nucleotides to the primer. It reads the parental template and builds the new strand only in the 5′ to 3′ direction.
The two parental DNA strands run in opposite directions. This arrangement is called antiparallel orientation.
Because DNA polymerase can synthesize in only one direction, the two new strands cannot be made in exactly the same manner. One is produced continuously, while the other is produced in short sections.
Leading-strand synthesis
The leading strand is made continuously toward the moving replication fork.
After one primer is placed, DNA polymerase follows helicase and keeps adding nucleotides. The direction in which the template is exposed matches the direction in which polymerase can build the new strand.
This allows synthesis to continue with relatively few interruptions.
A sliding-clamp protein helps hold DNA polymerase against the template. Without this clamp, the polymerase would detach more often, slowing the copying process.
In eukaryotic nuclear DNA replication, polymerase epsilon is commonly linked with leading-strand synthesis. The exact division of work between polymerases can be more complex than a simplified classroom model suggests.
Lagging-strand synthesis
The lagging strand is made discontinuously, away from the advancing replication fork.
As helicase exposes more template DNA, primase repeatedly adds new primers. DNA polymerase extends each primer until it reaches the previous fragment.
These short newly made sections are called Okazaki fragments.
The lagging strand does not remain fragmented. Later enzymes remove the RNA primers, replace them with DNA, and join the sections into one continuous strand.
Eukaryotic Okazaki fragments are commonly around 180 to 200 base pairs long. Bacterial fragments are generally longer, often measuring roughly 1,000 to 2,000 nucleotides, though their exact lengths vary by organism and experimental conditions.
The continuous and discontinuous patterns do not mean one strand is copied completely before the other begins. Both are copied at the same replication fork, with proteins coordinating their movements.
The lagging-strand template may loop so its polymerase can move with the rest of the replisome even though DNA is being produced in the opposite orientation relative to fork movement.
6) RNA primers are removed and replaced with DNA
Once DNA polymerase has extended the primers, the RNA sections must be removed. Other enzymes cut out the RNA and fill the resulting spaces with DNA nucleotides.
The exact proteins vary between bacteria and eukaryotes.
In many bacteria, DNA polymerase I removes RNA primers with its exonuclease activity and fills the gaps with DNA. In eukaryotes, RNase H and flap endonuclease 1 help process the primers, while a DNA polymerase fills the missing region.
Primer removal creates another difficulty on the lagging strand. Replacing an RNA primer with DNA connects the nucleotide sequence, but the sugar-phosphate backbone may still contain an unsealed break called a nick.
That break must be closed before the new strand becomes a complete DNA molecule.
Primer processing is especially challenging at the ends of linear eukaryotic chromosomes. When the final RNA primer is removed from the end of a lagging strand, there may be no upstream 3′ end available for DNA polymerase to extend.
This is known as the end-replication problem.
Cells address it with chromosome-end structures called telomeres and, in certain cell types, an enzyme called telomerase. Telomerase extends telomeric DNA so chromosome ends are not rapidly lost each time cells divide.
Telomere handling is often taught separately from the seven basic steps, but it arises directly from the primer-removal stage of linear chromosome replication.
7) DNA ligase seals the fragments and the new DNA is checked
DNA ligase joins neighboring DNA sections by sealing breaks in the sugar-phosphate backbone. Its action turns the lagging strand’s processed Okazaki fragments into a continuous DNA molecule.
DNA ligase forms a phosphodiester bond between the 3′ hydroxyl end of one fragment and the 5′ phosphate end of the next.
It does not usually add a long sequence of missing nucleotides. DNA polymerase fills the missing sequence, while ligase closes the final nick.
This distinction can prevent a common misunderstanding:
- Polymerase builds DNA.
- Ligase seals adjacent DNA sections.
Proofreading also occurs during synthesis. Many replicative DNA polymerases check whether the most recently added nucleotide pairs correctly with the template.
When an incorrect nucleotide is found, the polymerase can remove it through 3′ to 5′ exonuclease activity and insert the correct one. This correction happens while the strand is being built rather than only after the chromosome has been copied.
Base selection and polymerase proofreading reduce replication errors to very low levels. Additional mismatch-repair systems examine newly replicated DNA and correct some errors that escape polymerase proofreading.
Replication ends when the replication forks finish copying their assigned regions. In bacteria with circular chromosomes, forks eventually meet within a termination region. In eukaryotes, neighboring forks merge as the spaces between active origins are completed.
The finished products are two double-stranded DNA molecules. Each consists of:
One strand inherited from the parental molecule.
One strand made during the current replication cycle.
Why is DNA replication called semiconservative?
DNA replication is semiconservative because each resulting DNA molecule preserves one strand from the original double helix and contains one newly synthesized strand.
The term combines “semi,” meaning half, with “conservative,” referring to preservation. Half of each daughter DNA molecule comes directly from the parental molecule.
Matthew Meselson and Franklin Stahl demonstrated this pattern in 1958 through experiments involving Escherichia coli grown with different nitrogen isotopes. Their results supported the semiconservative model over conservative and dispersive alternatives.
Semiconservative replication also explains how complementary base pairing passes genetic information from one cell generation to the next. Each old strand carries the sequence needed to produce a matching partner.
Suppose the template contains:
A–T–G–C–C–A
The new complementary strand will contain:
T–A–C–G–G–T
The original sequence is not copied by guessing or by reading a separate master record. The molecular pairing rules built into DNA provide the template.
Which enzymes take part in DNA replication?
DNA replication relies on a group of enzymes and structural proteins rather than one enzyme acting alone.
Helicase
Helicase opens the DNA double helix by separating complementary strands at the replication fork.
Topoisomerase
Topoisomerase relieves twisting and supercoiling ahead of the fork. In bacteria, DNA gyrase is a major topoisomerase involved in this work.
Single-strand binding proteins
These proteins hold the separated DNA templates open and reduce unwanted folding or re-pairing.
Primase
Primase makes short RNA primers that provide the 3′ end needed for DNA synthesis to begin.
DNA polymerase
DNA polymerase selects and joins complementary DNA nucleotides. Replicative polymerases also proofread many newly added bases.
Primer-removal enzymes
RNase H, flap endonucleases, bacterial DNA polymerase I, and related proteins remove RNA primers or process the remaining flaps, depending on the organism.
DNA ligase
Ligase seals nicks in the DNA backbone, joining processed Okazaki fragments into one strand.
Sliding clamp and clamp loader
The sliding clamp holds polymerase on the DNA, allowing it to copy long stretches without falling off. The clamp loader places that ring-shaped clamp around DNA.
What is the difference between leading and lagging strands?
The leading strand is synthesized continuously toward the replication fork, while the lagging strand is synthesized in short Okazaki fragments away from the fork.
This difference comes from two features of DNA:
The parental strands run antiparallel to each other.
DNA polymerase builds only from 5′ to 3′.
The leading-strand template has an orientation that allows polymerase to follow the fork. The lagging-strand template faces the other way, so polymerase must repeatedly restart on newly exposed DNA.
Both new strands are chemically normal DNA when replication is complete. The names describe how they are made, not their quality or biological value.
Does proofreading happen only after replication?
No. A large part of proofreading occurs while DNA polymerase is building the new strand.
A correctly paired nucleotide fits the polymerase more readily than an incorrect one. If a mismatch is added, many replicative polymerases move the faulty end to a proofreading site, remove the incorrect nucleotide, and resume synthesis.
Polymerase proofreading can improve copying accuracy by roughly 100- to 1,000-fold. Combined with nucleotide selection, it can reduce the mismatch frequency to around one incorrect base per billion nucleotides before later repair systems act.
Post-replication mismatch repair provides another check. It recognizes certain distortions or mismatched bases left in newly made DNA and replaces the faulty section.
Errors that escape both proofreading and repair may become permanent mutations after another round of replication.
Is DNA replication the same in prokaryotes and eukaryotes?
The core logic is similar in both groups, but chromosome structure and protein names differ.
Both systems use origins, helicases, primases, polymerases, binding proteins, sliding clamps, primer-removal enzymes, topoisomerases, and ligases. Both also produce leading and lagging strands.
Bacteria usually have a circular chromosome with one main replication origin. Their replication can proceed around the chromosome until the two forks meet.
Eukaryotes contain multiple linear chromosomes. Each chromosome has many origins, allowing numerous sections to be copied at once. Eukaryotic DNA is also packaged with histone proteins, so chromosome copying includes the removal and reassembly of chromatin around the newly formed DNA.
Eukaryotic cells face the added problem of replicating chromosome ends. Telomeres and telomerase help manage this issue in cells where continued division requires telomere maintenance.
The enzyme names may also differ. Bacterial DNA polymerase III performs most chromosome synthesis, while eukaryotic cells mainly rely on polymerases alpha, delta, and epsilon for nuclear DNA replication.
How can the seven steps be remembered?
A simple memory sequence is:
Start, unzip, stabilize, prime, build, replace, seal.
Each word corresponds to one stage:
- Start: Origin recognition
- Unzip: Helicase opens the helix
- Stabilize: Binding proteins hold strands apart
- Prime: Primase makes RNA primers
- Build: Polymerase adds DNA nucleotides
- Replace: RNA primers are exchanged for DNA
- Seal: Ligase joins fragments and proofreading protects accuracy
This memory aid is useful for exams, but the real process is not a neat single-file sequence. Helicase may be opening one section while polymerase copies another and ligase closes an earlier fragment.
Common mistakes when explaining DNA replication
One common error is saying that helicase “cuts DNA in half.” Helicase separates the two strands by disrupting hydrogen bonds between base pairs. It does not divide the sugar-phosphate backbone down the middle.
Another is claiming that DNA polymerase can begin a new strand independently. Replicative DNA polymerases need a primer with a free 3′ hydroxyl group.
Students may also assume the lagging strand is made in the 3′ to 5′ direction. It is not. Every new DNA strand is synthesized 5′ to 3′. The lagging strand appears to move against the fork because it is made as separate fragments.
DNA ligase is sometimes described as the enzyme that fills every gap. Polymerase supplies missing nucleotides; ligase seals the final backbone break.
Proofreading should not be placed solely at the very end. Much of it takes place immediately after a nucleotide is added.
The finished copy carries the genome into the next cell generation
The seven basic steps of DNA replication turn one double helix into two nearly identical DNA molecules. Origins mark where copying begins. Helicase opens the parental molecule, binding proteins stabilize the templates, and primase gives polymerase a place to start.
DNA polymerase then builds the leading and lagging strands through complementary base pairing. Temporary RNA primers are removed, missing regions are filled with DNA, and ligase seals the remaining breaks. Proofreading and repair lower the chance that copying mistakes will become lasting mutations.
Behind this orderly sequence is a closely coordinated molecular system working across billions of base pairs. Its accuracy allows cells to divide, tissues to grow, and genetic information to pass from one cell generation to the next.